Abstract
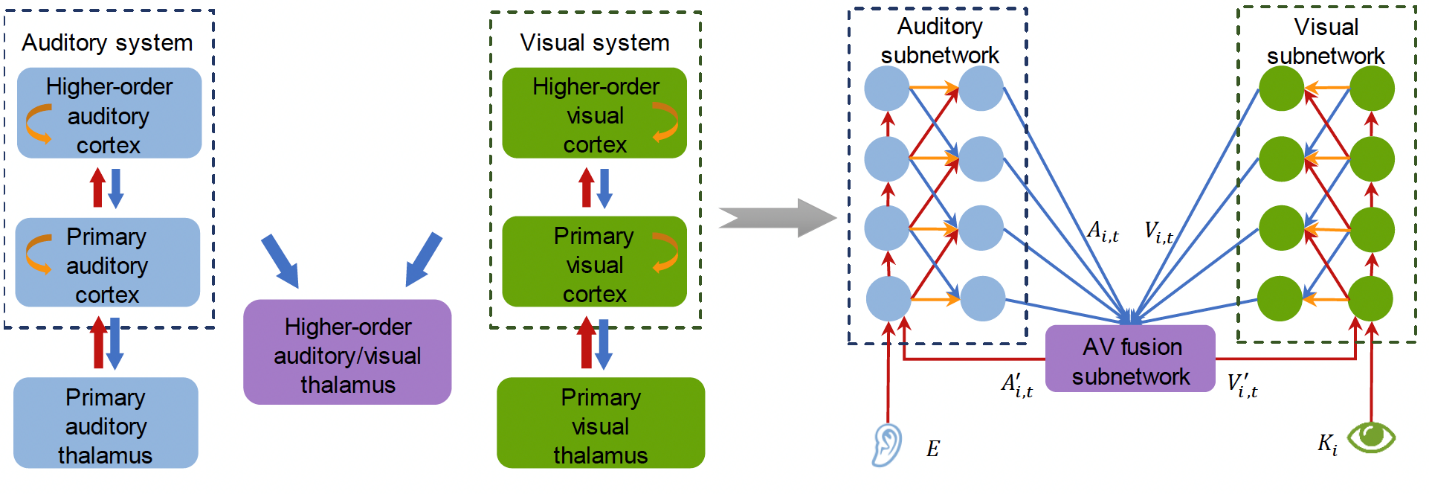
Audio-visual approaches involving visual inputs have laid the foundation for recent progress in speech separation. However, the optimization of the concurrent usage of auditory and visual inputs is still an active research area. Inspired by the cortico-thalamo-cortical circuit, in which the sensory processing mechanisms of different modalities modulate one another via the non-lemniscal sensory thalamus, we propose a novel cortico-thalamo-cortical neural network (CTCNet) for audio-visual speech separation (AVSS). First, the CTCNet learns hierarchical auditory and visual representations in a bottom-up manner in separate auditory and visual subnetworks, mimicking the functions of the auditory and visual cortical areas. Then, inspired by the large number of connections between cortical regions and the thalamus, the model fuses the auditory and visual information in a thalamic subnetwork through top-down connections. Finally, the model transmits this fused information back to the auditory and visual subnetworks, and the above process is repeated several times. The results of experiments on three speech separation benchmark datasets show that CTCNet remarkably outperforms existing AVSS methods with considerably fewer parameters. These results suggest that mimicking the anatomical connectome of the mammalian brain has great potential for advancing the development of deep neural networks.
|
Paper Link: https://ieeexplore.ieee.org/document/10487874
|