2024年9月25日,清华大学自动化系、清华-IDG/麦戈文脑科学研究院于国强团队与合作者在Neuron期刊共同发表题为"Data Science and its future in large neuroscience collaborations"的文章,调研并总结了目前脑科学研究中数据科学实践与研究存在的问题,并据此提出切实有效的改进建议,从而使脑数据科学成为脑科学发展的促进而不是障碍因素。此建议期望减小不同脑科学团队在科学研究过程中数据管理与分析之间的巨大差异,消除合作过程中的障碍,充分发掘数据的价值,加强科学研究的可重复性。
现代脑科学研究常常依赖于庞大复杂的数据集,脑成像数据、基因组数据和大型电生理记录通常与复杂行为相结合,以进一步理解大脑如何运作;在医学科学中,现代统计和人工智能模型可以通过识别大脑结构、活动或相关遗传标记中的模式,帮助诊断和治疗神经系统疾病。因此脑数据科学是现代脑科学不可或缺的一部分。于国强团队和合作者对大型国际脑科学项目近500名科研人员的做了一个匿名的详细调查,发现了脑数据科学实践和研究中的一系列问题。调研结果表明,现有的大型脑科学团队组织数据的主要机制仍是零散的Slacks/eMails和网络传输,多数研究者虽然了解领域内的规范性传输工具,但使用十分有限。与此同时,大约半数的团队发布数据和代码的比例小于研究过程中总量的80%,且大量存在数据处理过程不明确、代码审查率低的问题。在团队实验人员中,少数具有一定的代码能力。整体而言,现有的数据层面训练较为缺乏,超过半数人员未执行数据及代码标准。
针对调查中发现的问题,结合脑科学与数据科学融合发展的新趋势,于国强团队和合作者提出了促进脑数据科学发展的若干项有效措施和建议。数据整合方面,未来的神经科学家将不仅在自身专业领域具备深厚的知识储备,同时也应该在数据管理和分析方法领域具备基本素养。同时提出三条建议:一是新的资助计划可以吸引更多的数据科学专家进入神经科学领域,从而促进编程和数据分享的实践;二是可以提前邀请数据科学家参与到数据的收集环节,并使他们参与到实验室的日常会议中;三是建立统一的一个或若干个脑数据科学研究中心可以助力大型脑科学项目的整合和协调,同时该中心应当向整个国家的科研人员开放,提供服务。数据共享方面,可以通过以下政策来促进数据和代码的标准化:一是倡议使用已经存在的代码,避免重复开发,同时促进各方合作和交流;二是统一代码和数据的共同规范;三是建议科研资助机构或其他第三方组织对数据处理流程予以基本评估并颁发许可;四是倡导作者与使用者进行互动时及时发布相关代码和数据,减少误导结论的风险;五是建议在商业云生态系统之外,建立新的基础设施。研究人员培训方面,则可以通过加大新一代研究人员的培训拨款力度、提供具体的培训机会、开发共享的培训资料等方式提升研究者的数据科学素养。
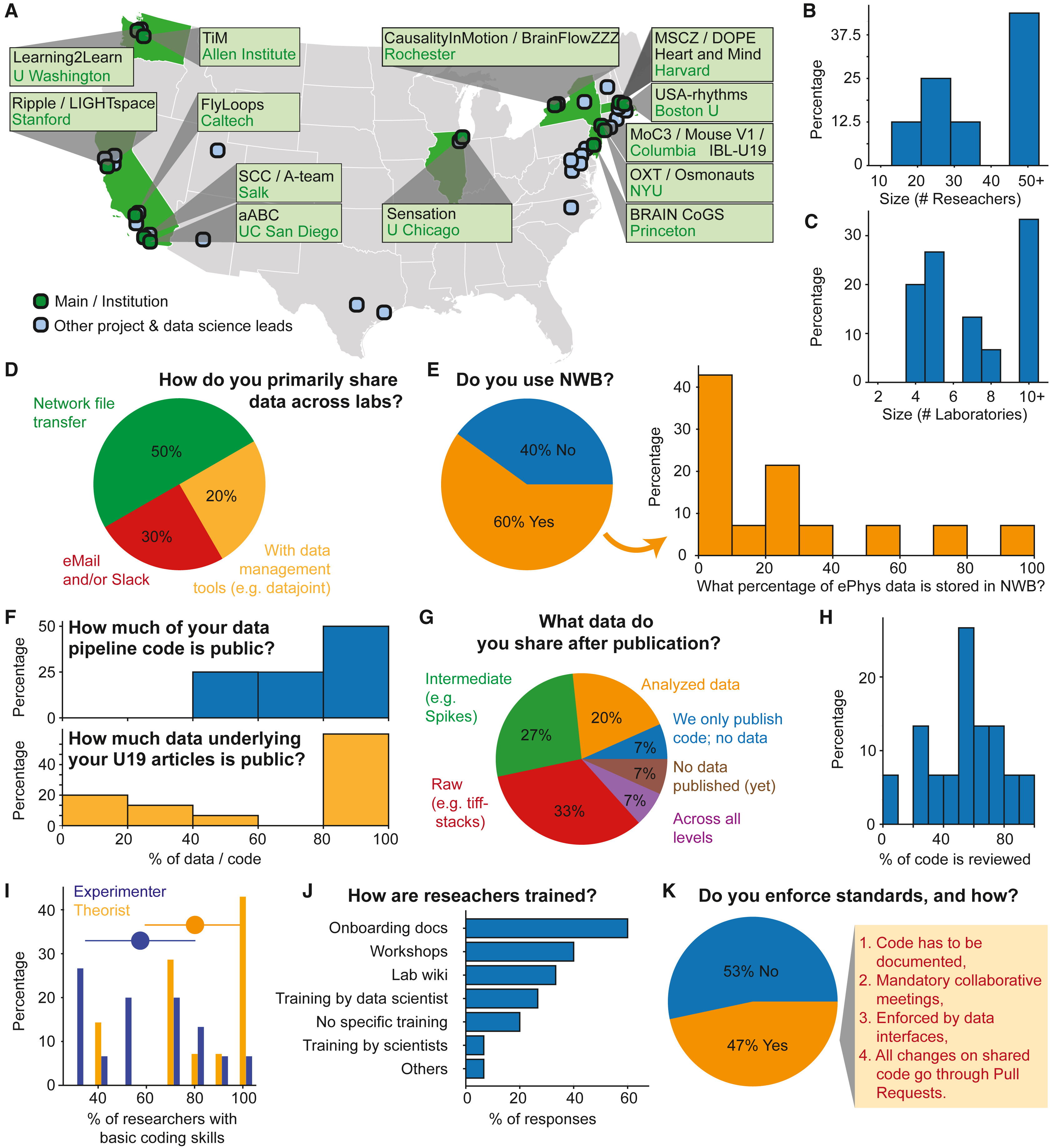
图1. 对神经科学研究团队的调查结果
最后,该文章对现代脑科学中的数据科学发展进行了讨论与总结。现代脑科学通常依赖于大规模和高复杂度的数据集,这些数据集从根本上加快了对神经系统的理解,并以前所未有的速度发展起来。但是,该领域目前仍存在缺乏代码和数据组织管理规范、数据科学基金不到位等发展瓶颈,本文对大型脑科学合作的调查便揭示了数据科学前进发展的基本挑战。由此,作者倡议建立共享社区,以及完善数据集和数据分析工具的基础设施、数据和代码使用规范等,这些结构性调整将以意想不到的方式改变神经科学发展的进程。该文章呼吁大家行动起来,共同应对诸多挑战,为大型脑科学合作中数据科学的发展添砖加瓦。
清华大学自动化系长聘教授、清华-IDG/麦戈文脑科学研究院研究员于国强、美国普林斯顿神经科学研究所Manual Schottdorf博士与美国华盛顿大学计算神经科学中心助理教授Edgar Y. Walker为本文共同通讯作者。
|
原文链接:https://www.cell.com/neuron/fulltext/S0896-6273(24)00641-X |